
Data generation today is never-ending—we simply generate massive volumes of data. It can be in the form of reports, emails, pictures, and videos, to name a few. As a whole, this is known as Big Data. As the name implies, this data is too massive for traditional databases to handle. For this, we have the Hadoop framework. Hadoop, in turn, uses Hive and Pig to process and analyze all of this Big Data. Users also have a lot of questions: Are they both the same, and if not, when should one tool be used over the other? We answer these questions (and more) in this Hive vs. Pig article.
What is Hadoop?
Big Data consists of data in different formats, such as Excel spreadsheets, reports, log files, videos, etc. Traditional databases failed to store, process, and analyze Big Data. The Hadoop framework made this job easier with the help of various components in its ecosystem.
The Hadoop Distributed File System (HDFS) is where we store Big Data in a distributed manner. Hadoop MapReduce is responsible for processing large volumes of data in a parallelly distributed manner, and YARN in Hadoop acts as the resource management unit.
Apart from those Hadoop components, the Hadoop ecosystem has other capabilities that help with Big Data processing. The following comprise the Hadoop ecosystem:
- HDFS
- HBase
- Sqoop
- Flume
- Spark
- Hadoop MapReduce
- Pig
- Impala
- Hive
- Cloudera Search
- Oozie
- Hue
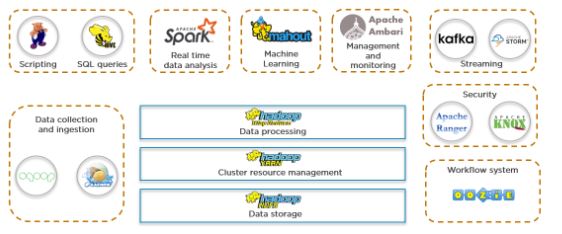
Fig: Hadoop Ecosystem
Hive and Pig are the two integral parts of the Hadoop ecosystem, both of which enable the processing and analyzing of large datasets. There are some critical differences between them both. Let’s dive deeper into these two platforms to see what they are all about. The Hive vs. Pig debate is a hot topic in the tech world.

Fig: Hive vs. Pig
Before we move on to comparing Hive and Pig, let’s look into Hive and Pig individually.
Introduction to Hive
Here, let’s have a look at the birth of Hive and what exactly Hive is.
Birth of Hive
Facebook played an active role in the birth of Hive as Facebook uses Hadoop to handle Big Data. Hadoop uses MapReduce to process data. Previously, users needed to write lengthy, complex codes to process and analyze data. Not everyone was well-versed in Java and other complex programming languages. On the other hand, many individuals were comfortable with writing queries in SQL. For this reason, there was a need to develop a language similar to SQL, which was well-known to all users. This is how the Hive Query Language, also known as HiveQL, came to be.
What is Hive in Hadoop?
Hive is a data warehouse system used to query and analyze large datasets stored in HDFS. Hive uses a query language called HiveQL, which is similar to SQL.

Fig: Hive operation
The image above demonstrates a user writing queries in the HiveQL language, which is then converted into MapReduce tasks. Next, the data is processed and analyzed. HiveQL works on structured data, such as numbers, addresses, dates, names, and so on. HiveQL allows multiple users to query data simultaneously.
So, what do we do with semi-structured and unstructured data like emails, images, videos? Enter Apache Pig.
Introduction to Pig
Pig also came into existence to solve issues with MapReduce. Let’s take a close look at Apache Pig.
Birth of Pig
Although MapReduce helped process and analyze Big Data faster, it had its flaws. Individuals who were unfamiliar with programming often found it challenging to write lengthy Java codes. Eventually, it became a difficult task to maintain and optimize the code, and as a result, the processing time increased.
This was the reason Yahoo faced problems when it came to processing and analyzing large datasets. Apache Pig was developed to analyze large datasets without using time-consuming and complex Java codes. Pig was explicitly developed for non-programmers.
What is Pig in Hadoop?
Pig is a scripting platform that runs on Hadoop clusters, designed to process and analyze large datasets. Pig uses a language called Pig Latin, which is similar to SQL. This language does not require as much code in order to analyze data. Although it is similar to SQL, it does have significant differences. In Pig Latin, 10 lines of code is equivalent to 200 lines in Java. This, in turn, results in shorter development times.
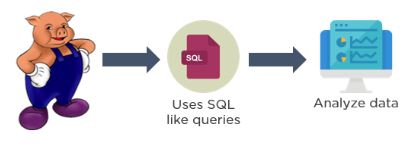
Fig: Pig operation
What stands out about Pig is that it operates on various types of data, including structured, semi-structured, and unstructured data. Whether you’re working with structured, semi-structured, or unstructured data, Pig takes care of it all.
Many people wonder what makes Pig better than Hive. Hive does have its advantages over Pig in a few ways—and we’ll compare these different features—to help you make a more informed decision when it comes to choosing which platform best suits your requirements.
Looking forward to becoming a Hadoop Developer? Check out the Big Data Hadoop Certification Training course and get certified today.
Hive vs. Pig
The following table compares the advantages of Hive with the advantages of Pig :
|
Features |
 |
 |
|
1. Language |
Hive uses a declarative language called HiveQL |
With Pig Latin, a procedural data flow language is used |
|
2. Schema |
Hive supports schema |
Creating schema is not required to store data in Pig |
|
3. Data Processing |
Hive is used for batch processing |
Pig is a high-level data-flow language |
|
4. Partitions |
Yes |
No. Pig does not support partitions although there is an option for filtering |
|
5. Web interface |
Hive has a web interface |
Pig does not support web interface |
|
6. User Specification |
Data analysts are the primary users |
Programmers and researchers use Pig |
|
7. Used for |
Reporting |
Programming |
|
8. Type of data |
Hive works on structured data. Does not work on other types of data |
Pig works on structured, semi-structured and unstructured data |
|
9. Operates on |
Works on the server-side of the cluster |
Works on the client-side of the cluster |
|
10. Avro File Format |
Hive does not support Avro |
Pig supports Avro |
|
11. Loading Speed |
Hive takes time to load but executes quickly |
Pig loads data quickly |
|
12. JDBC/ ODBC |
Supported, but limited |
Unsupported |
Fig: Hive vs. Pig Comparison Table
Both Hive and Pig are excellent data analysis tools—one is not necessarily better than the other, but they do have different capabilities and features. Depending on your job role, business requirements, and budget, you can choose either of these Big Data analysis platforms.
Do you have any questions for us concerning Hive vs. Pig? Please ask any questions in the comment section of this article, and we'll have our experts answer them for you.
Want to Learn More About How to Apply These Tools to Your Career?
If you want to boost your career in Big Data processing with these widely popular tools, check out our Big Data Hadoop Certification Training course today!
